Docker와 EC2 Spot Instance로 병렬 작업 수행하기
최근 뉴스 기사를 크롤링 할 일이 있었다. 한 1년 정도의 데이터가 필요했는데, 그 많은 기사를 긁으면 한 세월이 걸릴 것이 분명했다. 더 빠르게 작업을 완료하기 위해 병렬적으로 크롤링을 하기로 했고, 설정 코스트를 최소화하기 위해 Docker와 AWS를 이용하기로 했다. 이 둘 모두 엄청 최신 기술은 아니지만 최근 들어 데이터 분석을 종종 하면서 병렬로 작업을 수행해야 할 일들이 늘어나고 있어서, 다시 제대로 정리하는 김에 EC2 Spot Instance와 Docker를 이용하여 크롤링을 진행해보았다.
병렬 작업에 대한 구조 디자인
병렬 작업 처리를 위해서는 우선 작업을 어떻게 쪼갤지를 정해야 한다. 나는 날짜를 작업의 단위로 삼았다. 다른 이유보다는 크롤링할 기사에 대한 URL 목록을 받아오기 위해서는 날짜별로 쿼리를 주어야 했기 때문이다.
다만 날짜를 단위로 삼을 경우 1년 치 데이터를 수집하기 위해서는 총 365개의 task가 생기는데, 이를 N개의 노드에게 어떻게 분배하는가에 대한 문제가 발생한다. 그저 적당히 쪼개어서 노드가 10개라면 36개씩 분배하는 방법도 있겠지만, 작업별 수행 시간을 미리 알 수 없고 또 그 시간의 차이가 크다면 좋은 방법은 아니다. 단적으로 9개의 노드는 1시간 만에 작업을 완료했는데, 나머지 1개의 노드가 10시간이 걸린다면 총 수행 시간은 10시간이 될 수 있다.
좋은 방법은 노드마다 작업을 하나씩 수행하다가 그 작업이 끝나면 다음 작업을 받아 수행하는 것이다. 작업의 리스트는 큐(queue) 형태로 저장하고, 이를 모두가 공유하도록 설계를 하면 된다. 노드마다 작업의 수는 고르지 않지만 작업 소요 시간을 모르는 상황에서 전체 작업 시간은 가장 최소화될 것이다.
 이상적인 병렬 처리의 모습
이상적인 병렬 처리의 모습
이를 구현하기 위해서는 크게 2가지 방법이 있다.
- 작업 노드에서 자체적으로 기 작업이 끝나면 새로운 작업을 큐에서 받아와서 수행 (pull-based)
- 마스터 노드를 두고, 작업 노드들을 체크하며 IDLE 상태라면 작업을 수행하도록 명령 (push-based)
1번의 방법이라면 큐 시스템을 설계해야 한다. AWS SQS 같은 서비스를 이용할 수도 있겠다. 2번 방법이라면 마스터 노드가 작업 노드들의 정보와 접속 권한을 가지고 있어야 한다. 나는 2번 방법을 사용하기로 했다. 작업 노드에 장애가 발생할 경우 1번의 경우 문제를 인지하기 쉽지 않지만, 2번 방법을 이용하면 장애 감지까지 편하다는 장점이 있었고, 무엇보다 Docker Remote API (Docker Engine API)를 이용하면 ‘작업 노드를 체크하고 작업을 수행하도록 명령하는 것’을 매우 쉽게 구현할 수 있어서다.
Docker는 RESTFul 형태로 명령을 수행할 수 있도록 API를 제공한다. 흔히 사용하는 docker ps, docker images, docker run 등 모든 커맨드를 curl을 이용해서도 실행시킬 수 있고, 외부에서도 명령을 보낼 수 있다. 언어별로 docker API를 wrapping한 SDK가 있으며, 특히 python은 공식적으로 SDK를 제공한다.
Scrapy로 크롤러를 만들고 Docker로 패키징하기
먼저 크롤러를 만들어야 한다. Scrapy를 이용했는데, 이 라이브러리를 이용하면 python으로 빠르고 효율적인 크롤러를 개발할 수 있다. 크롤러는 arg를 통해 크롤링 할 날짜를 받고, 해당 날짜의 기사를 전부 긁었다면 정상 종료되도록 개발하였다. 기사 데이터는 로컬 파일에 JSON type으로 저장하도록 했다. 전체 작업이 완료되면 gzip으로 압축하여 AWS S3에 데이터를 업로드한다. 환경변수에는 S3 업로드를 위한 버킷 이름, access key, secret key 를 받도록 하였다. 이를 shell 로 실행하려면 다음과 같은 명령어를 주면 된다.
env AWS_BUCKET=<S3_BUCKET_NAME> \
env AWS_ACCESS_KEY_ID=<AWS_ACCESS_KEY_ID> \
env AWS_SECRET_ACCESS_KEY=<AWS_SECRET_ACCESS_KEY> \
scrapy runspider spiders/naver_news.py -a date=20190101
하지만 이 명령어를 노드마다 실행하게 하지는 않을 것이다. 만약 ssh 등으로 실행한다면 그전에 python3, scrapy, virtualenv 등을 설치하고 환경을 갖추어 주어야 하는데 이는 너무 불편하다. 그렇다. Docker로 scrapy를 패키징 해줄 필요가 무척 있었다.
다만 약간의 문제가 있는데, scrapy는 library 형태가 아닌 framework로, 자체 scrapy runspider 명령어를 통해 수행해준다는 것이다. Python docker image를 사용하려면 scrapy를 시작시킬 엔트리용 파일을 작성할 필요가 있었다. 이에 scrapy에서는 공식적으로 CrawlerProcess 라는 클래스를 제공한다. 이를 이용하면 scrapy 프로세스를 python으로 작성하고 관리할 수 있다. 실제 scrapy 라이브러리의 내부 setup.py를 확인해보면 cmdline.py 의 execute 함수를 호출함을 볼 수 있는데, 이 함수 내에서도 CrawlerProcess 클래스를 이용한다.
# run-scrapy.py
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from newscrawler.spiders.naver_news import NaverNewsSpider
import os
process = CrawlerProcess(get_project_settings())
process.crawl(NaverNewsSpider, date=os.environ['DATE'])
process.start()
process.join()
단순하게 하나의 spider에 대해 crawl을 시작하고 전부 완료되면 종료하도록 python 코드를 작성하고, 이를 Dockerfile에서 엔트리 포인트로 사용하였다.
FROM python:3.6
WORKDIR /usr/src/app
COPY requirements.txt ./
RUN pip3 install -r requirements.txt
COPY . .
CMD ["python", "run-scrapy.py"]
작업을 위한 EC2 AMI 만들기
어떤 환경에서도 동작할 수 있게 docker image로 만들어 두긴 했지만, docker 실행을 위해서 환경 구성이 조금 더 필요하다. AWS ECS를 사용하면 뭔가 잘 될 것 같기는 하지만 러닝 코스트가 더 클 것 같아서 그냥 ubuntu EC2를 띄워 필요한 것들을 설치하고 AMI로 만들기로 했다.
해야 할 일들은 다음과 같았다.
- Docker 설치
- 작업용 docker image 빌드
- 외부에서 docker 명령어를 작업 노드에 사용할 수 있게 포트 오픈
1번과 2번은 크게 이야기할 것이 없다. Docker를 설치하고 크롤러 repo를 받아와 빌드까지 무사히 마쳤다.

그럼 3번에 대해서 이야기할 텐데, 위에서 잠깐 이야기하였지만 docker는 RESTFul 형태로 API를 제공하며, 외부에서도 명령을 보낼 수 있다. 나는 이 점을 이용하여 ssh 접속 없이도 작업 노드의 docker socket에 바로 접속하여 위에서 만든 이미지를 실행하고자 했다. 조금 더 자세히는 master 노드가 작업 노드의 IP주소를 가지고 있고, 작업 노드들에게 docker run 명령어를 원격으로 실행시켜 크롤링을 수행하고, 해당 작업이 끝나 컨테이너가 종료되면 다음 task를 바탕으로 다시 docker를 실행시키는 구조를 만들고자 했다.
이를 위해서는 먼저 외부에 socket을 열어주어야 한다. 다만 보안 이슈가 있었는데, 0.0.0.0 으로 전 세계에 오픈 해 버릴 경우 비트코인 채굴기 등에 악용 될 소지가 있었다. 이를 막으려면 VPN을 구성하거나, Docker Engine API에서 제공하는 OpenSSL CA를 사용할 수 있다. 후자가 적합해 보였지만, 이또한 귀찮았기에 그냥 0.0.0.0으로 열어버린 뒤 EC2에서 제공하는 Security group을 이용해서 내 IP만 허용하고 나머지 접속을 막아버리기로 했다.
그럼 이제 docker의 설정을 바꿔서 0.0.0.0 을 여는 일만 남았다. 이 또한 docker의 공식 문서에 친절하게 써있기에 무리 없이 진행할 수 있었다. /etc/systemd/system/docker.service.d/override.conf 파일을 만들고 아래와 같이 작성하면 된다.
[Service]
ExecStart=
ExecStart=/usr/bin/dockerd -H fd:// -H tcp://0.0.0.0:2375
모든 환경 구성을 마쳤으면 EC2 EBS에 들어가 스냅샷을 만들어주고, 스냅샷이 생성되면 private AMI를 만들어주면 된다.

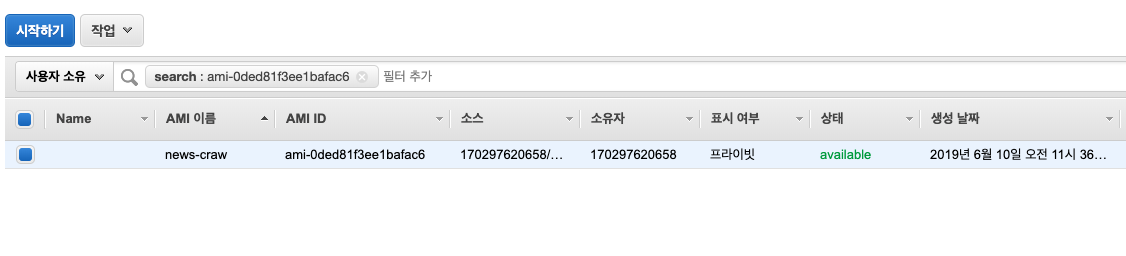
다음에는 스팟 요청에 들어가 요청을 누른 뒤, 방금 만들었던 AMI을 선택해주고 원하는 사양과 숫자를 정한 뒤 시작을 하면 된다.
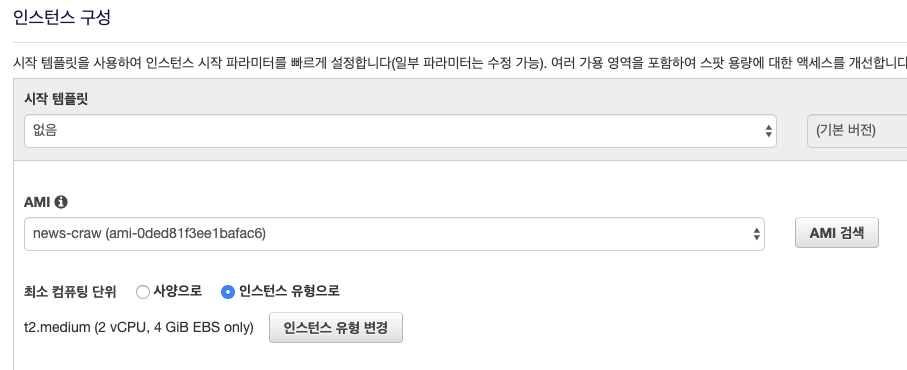
보안 구성도 까먹지 말자. Docker tcp 포트인 2375를 내 IP에서만 허용하게 설정하였다.
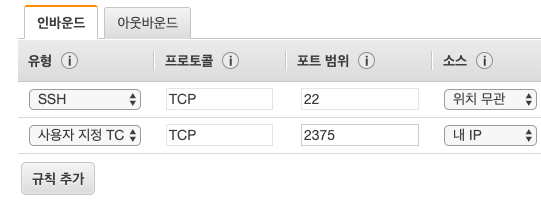
나는 10개의 t2.medium 인스턴스를 생성하였다. 인스턴스들의 IP를 가져와서 어딘가에 기록해두자. 다수의 인스턴스 풀을 사용한다면 EC2 API를 이용해서 IP 주소를 받아오도록 하면 더 좋을 것이다.
docker-py를 이용하여 노드마다 작업 분배하기
그럼 이제 작업 노드들에게 적당한 일거리를 분배해주는 친구가 필요하다. 지금까지 이 친구를 master 노드라고 불렀지만, 사실 그리 거창하게 작성하지는 않았다.
docker-py를 이용하여 원격으로 컨테이너를 실행하려면 다음과 같이 써주면 된다.
client = docker.DockerClient(base_url='tcp://%s:2375' % ip)
client.containers.run('image_name', environment=environment, name='container_name')
위 SDK는 기본적으로 동기적(Synchronous)으로 동작하므로 여러 개의 노드를 관리하기 위해서는 multi-thread(multi-process)를 사용해야 한다. python의 multiprocessing 패키지를 이용하면 이 또한 매우 쉽게 구현할 수 있다. 다만 멀티프로세스로 이를 개발 할 경우, 공유 자원 관리에 신경써주어야 한다. 우리가 신경 쓸 공유 자원이 있었던가? 있었다. 큐(queue) 형태로 관리한다고 했던 작업의 리스트가 그렇다.
하지만 python의 multiprocessing 패키지에는 concurrent queue도 제공한다. 아래처럼 사용할 수 있다.
from multiprocessing import Process, Queue
queue = Queue()
queue.put('task 1')
queue.put('task 2')
def process_entry(queue):
while not queue.empty():
print(queue.get())
p = Process(target=process_entry, args=(queue, ))
p.start()
Process, Queue, docker-py를 이용해서 날짜마다 task를 나누어 1년 치 데이터를 긁도록 명령하는 master process는 아래처럼 구성할 수 있다. 2018년 1월 1일부터 12월 31일까지 날짜를 generate한 뒤 queue에 넣어두고, 각 프로세스마다 queue에서 pop을 수행해 순차적으로 작업을 수행하도록 작성하였다.
import docker
from datetime import datetime, timedelta
from multiprocessing import Process, Queue
def process_entry(ip, queue):
client = docker.DockerClient(base_url='tcp://%s:2375' % ip)
while not queue.empty():
date = queue.get()
client.containers.run('news_craw', environment={
'AWS_ACCESS_KEY_ID': '<access-key>',
'AWS_SECRET_ACCESS_KEY': '<secret-key>',
'AWS_BUCKET': '<bucket>',
'DATE': date,
}, name='task_%s' % date)
nodes = [
'54.180.1.1',
'54.180.1.2',
...
]
if __name__ == '__main__':
queue = Queue()
d = datetime(year=2018, month=1, day=1)
while True:
if d.year == 2019:
break
queue.put(d.strftime('%Y%m%d'))
d += timedelta(days=1)
processes = []
for node in nodes:
p = Process(target=process_entry, args=(node, queue))
p.start()
processes.append(p)
for p in processes:
p.join()
위 코드를 통해 정말로 컨테이너가 잘 실행되는지 확인하려면 그냥 아무 노드나 하나 들어가서 docker ps를 해보면 된다. 컨테이너 name에 날짜를 같이 넣어주었는데, 이를 통해서도 현재 어떤 날짜의 데이터를 수집하고 있는지 확인할 수 있다.

Athena를 이용하여 데이터 조회하기
AWS Athena는 SQL을 이용하여 S3 데이터를 조회할 수 있는 서비스다. 비용은 스캔한 데이터의 양에 따라 부과된다. 데이터 타입으로 JSON을 제공하며 gzip으로 압축된 JSON도 조회할 수 있다. Apache Parquet를 사용하면 필요한 컬럼만 조회하여 보다 저 비용으로 데이터를 조회할 수 있고, S3 Object Key 네이밍에 따라 partioning 또한 가능하다. 무엇보다 서버리스로 매우 빠르게 결과를 조회할 수 있기 때문에, 데이터를 S3에서 관리한다면 분석시 매우 유용하게 사용할 수 있다.
CREATE EXTERNAL TABLE IF NOT EXISTS newsdata (
`oid` int,
`aid` int,
`time` string,
`title` string,
`content` string,
) PARTITIONED BY (`date` string)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://<s3-bucket>/'
위 처럼 스키마를 정의한 후 아래처럼 SQL을 작성하면 S3의 데이터를 잘 조회하여 결과를 뽑아준다.
SELECT date, count(*)
FROM default.newsdata
GROUP BY date
ORDER BY date
크롤링을 끝낸 후 데이터가 잘 들어갔는지 확인하기 위해 쿼리 결과를 matplotlib을 이용해 1년 치 그래프를 그려보았더니 아래처럼 나온다. 그래프가 굉장히 많이 요동치는 것처럼 보인다. 무엇일까? 설마 주말인가?
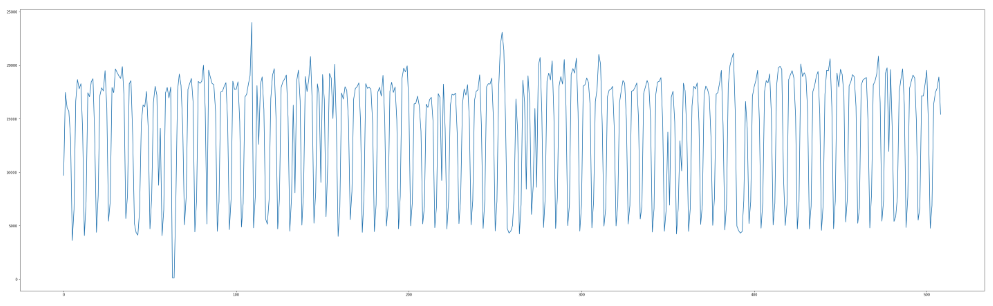
한 달 치 데이터를 그려보니 명확해 보인다. 혹시 몰라 2018년 1월 6일을 보니 토요일이다. 주말엔 기사 수가 확실히 적구나. 그래도 결과를 보니 크롤링은 정상적으로 잘 끝난 것 같다.
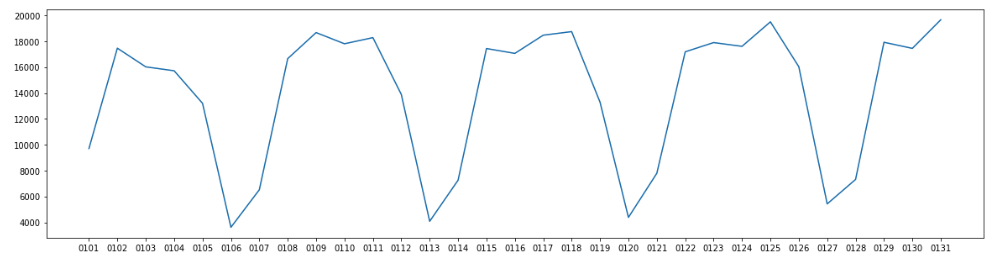
뉴스 기사 데이터는 확실히 RDBMS보다 S3 같은 Key-value storage에서 관리하는 것이 좋다고 생각한다. 다만 이처럼 다수의 데이터에 쿼리를 실행해보고 그래프를 보고자 하는 필요성이 가끔씩 있는데, Athena를 사용하면 정말 빠르게 결과를 확인할 수 있다.
이 글에서는 크롤링을 다루었지만, 이 외에도 AWS를 잘 사용하면 데이터 수집부터 분석까지의 작업을 매우 효율적으로 수행할 수 있다.
