Underneath DynamoDB
얼마 전 대학원 수업 때문에 Dynamo: Amazon’s Highly Available Key-value Store [1] 라는 논문을 읽을 일이 있었다. 사실 DynamoDB는 내가 원래부터 알고 있던 AWS에서 서비스되는 데이터베이스였고, DynamoDB를 공개하면서 함께 발표한 논문인 줄 알았다. 하지만 논문에서의 Dynamo와 현재의 AWS DynamoDB는 아래와 같은 차이가 있었다:
- Dynamo: Key-value Store; 2007년도에 논문을 통해 공개된 Amazon에서 내부적으로 사용하던 스토리지 시스템.
- DynamoDB: NOSQL 데이터베이스; Dynamo의 아이디어를 바탕으로 만든 서비스형 데이터베이스.
논문과 긁을 읽은 이후에 문득 DynamoDB가 써보고 싶어져 간단한 서비스를 DynamoDB를 이용해 실제로 만들어봤다. 그리고 그 과정속에서 느꼈던 것들을 공유하고 싶어 이 포스트를 쓰게 되었다. 이번 포스트에서는 논문에서 이야기하는 Dynamo의 핵심 아이디어와 현재 DynamoDB의 디자인을 함께 엮어서 다뤄보고자 한다. DynamoDB의 배경에는 어떤 것들이 있었는지, 또 어떤 principle를 바탕으로 만들어졌는지를 이야기해보고 싶다.
Dynamo의 핵심 아이디어
Dynamo는 2007년도에 Amazon이 제안한 Key-Value 스토리지 시스템이다. 지금은 더하겠지만 2007년도에도 Amazon은 수많은 트래픽에 시달렸었고, 이를 위해 수백만의 컴포넌트를 관리하고 있었다. 하지만 많은 사용자를 상대하는 만큼 장애가 발생하는 상황도 무시할 수 없을 만큼 많았다. 논문에 따르면 서버나 네트워크에 항상 작지만 큰 숫자의 장애가 발생했다고 한다. 즉 장애는 특이상황이 아니며, 정상적인 케이스로 보아야 한다는 것이다. 그렇기에 Amazon의 시스템은 장애가 발생해도 정상 동작하도록 만드는 것이 이들의 목표였다.
a. Write Availability Problem
데이터베이스, 혹은 스토리지 시스템에서 가용성availability을 높이기 위해서는 주로 replication을 이용한다. Replication에서 가장 신경 써야 할 문제는 데이터 간의 동기화를 어떻게 이룰 것인가에 있다. 기존의 데이터베이스에서는 보통 write operation에서 모든 노드에 데이터를 쓰고 동기화를 맞추며, read operation에서는 동기화가 되어있다는 가정하에 하나의 임의 노드에서 읽기를 수행하는 식으로 일관성consistency을 보장한다. 즉 write operation는 길게 read operation은 빠르게 하자는 정책인데, 실제 쿼리의 대부분은 read이기 때문에 전체적인 성능 향상에 도움을 준다.
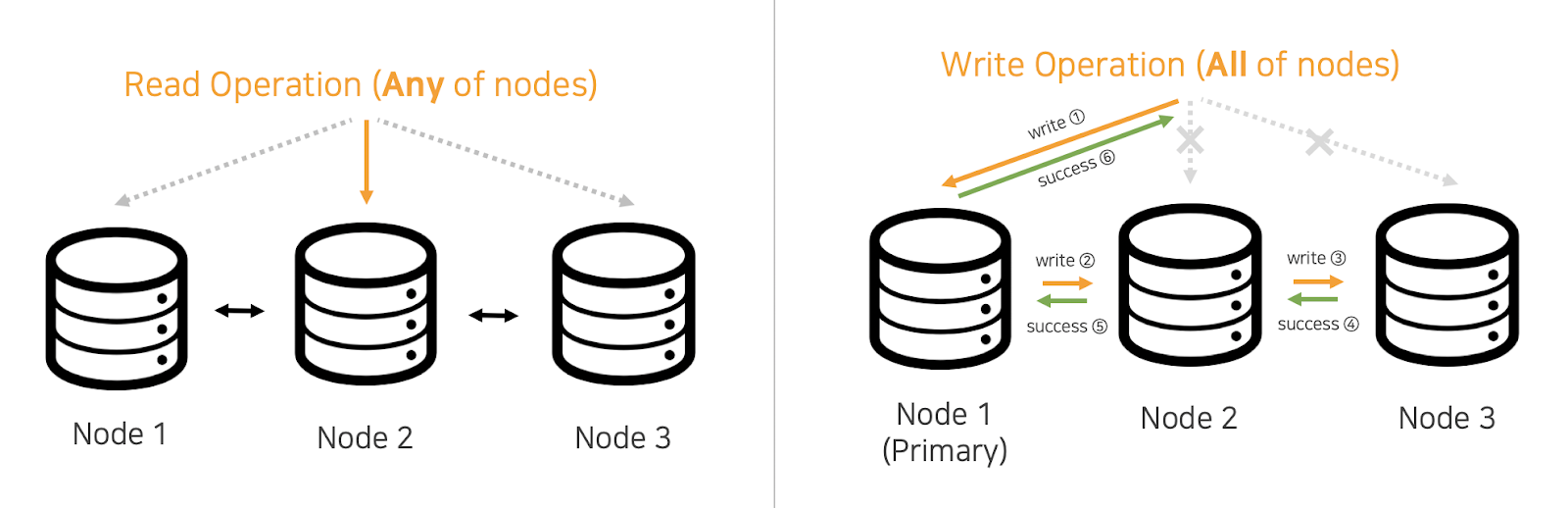 그림 1. 전통적인 데이터베이스의 replication 디자인. 1번 노드를 master, 2~3번 노드를 slave라고도 한다.
그림 1. 전통적인 데이터베이스의 replication 디자인. 1번 노드를 master, 2~3번 노드를 slave라고도 한다.
하지만 장애 상황에서는 문제가 달라진다. Read operation의 경우 하나의 노드에 장애가 발생해도 다른 노드에서 수행을 할 수 있다. 하지만 write operation에서는 일관성을 보장해야 하기에 장애가 발생한 노드가 명령을 정상 수행할 때까지 기다리거나, 혹은 모든 노드에 operation이 동작하지 않게 해야 한다. 이 디자인은 write operation에 대해 어떤 상황에서도 수행이 가능해야 한다는 가용성availability을 만족시키지 못하며, 이러한 문제점을 Write Availability Problem이라고 한다. 그리고 앞서 말했듯이 장애 상황은 Amazon에게 특이 케이스가 아니었다.
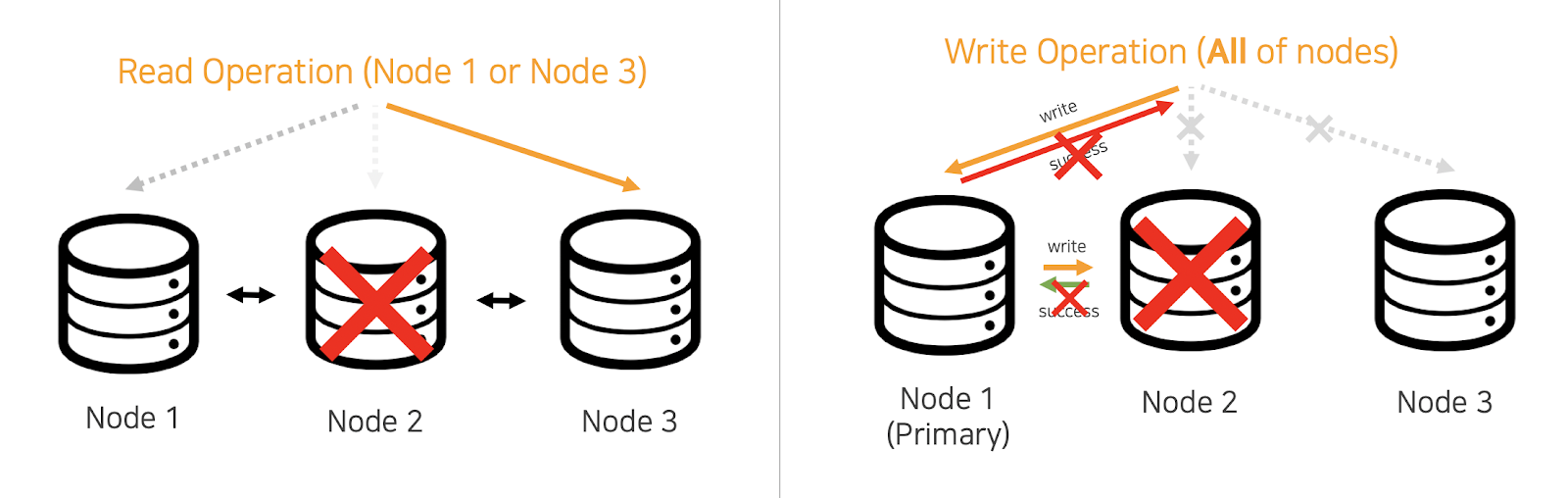 그림 2. 2번 노드가 장애가 난 상황.Write operation은 2번 노드가 복구될 때까지 정상 수행될 수 없다.
그림 2. 2번 노드가 장애가 난 상황.Write operation은 2번 노드가 복구될 때까지 정상 수행될 수 없다.
b. Eventual Consistency
Dynamo에서는 Write Availability Problem을 해결하기 위해 일관성consistency을 일부 희생하는 접근을 취한다. 다시 말해 모든 노드에 write operation이 완료되지 않아도 적당히 눈감아 주며 클라이언트에게 성공했다고 response를 보낸다. 예를 들어 총 3개의 replication이 있는 상황에서 1번과 3번 노드에서 write 수행이 50ms가 걸리고 2번 노드가 장애 상황으로 인해 2000ms가 걸린다고 하자. 이 상황에서 2번 노드에서 write가 완료되지 않아도 1번과 3번 노드에서만 성공을 하면 바로 클라이언트에게 성공했다고 메시지를 보내는 것이다. 그러면 2번 노드의 장애 상황에서도 50ms 안에 write operation이 수행될 수 있다.
이 정책에서는 클라이언트에서 write가 완료되었다는 메시지를 받은 이후 read를 수행해도 오래된 버전의 데이터를 반환할 수 있다. 즉, 순간적으로 노드간 서로 다른 버전의 데이터를 가지고 있을 수 있고, 이는 데이터베이스의 일관성 제약 조건에 어긋난다 (inconsistent). 하지만 중요한 점은 시간이 어느 정도 지나면 모든 노드에 write가 수행될 것이고, 결과적으로는 일관성이 지켜질 것이라는 것이다. 그리고 이를 Eventual Consistency라고 한다.
실제 서비스 환경에서 모든 데이터가 강한 일관성(항상 최신의 데이터)을 요구하지는 않는다. 예를 들어 상품의 재고나 평균 별점, 리뷰의 수 등은 예전 버전의 데이터를 보여줘도 큰 문제가 되지 않는다. Dynamo는 이처럼 강한 일관성을 요구하지 않는 어플리케이션을 타게팅하여 만들어졌다. 그리고 최근에도 많은 서비스들이 데이터의 특징에 따라 consistency level과 성능 사이에서 tradeoff를 하고 있는 것으로 알고 있다.
c. N, R, W 파라미터
Dynamo는 Write Availability를 위해 완전한 일관성 대신 Eventual Consistency만 보장한다. 그럼 정책으로 스토리지를 만든다고 하자. 3개의 replication 노드가 있다면 몇 개 이상부터 성공으로 간주하면 좋을까? Dynamo는 이 숫자들을 임의로 정하지 않고 사용자가 설정할 수 있는 파라미터로 만들었다. N은 replication 노드의 수, R은 읽기 작업이 성공으로 간주되기 위한 노드의 수, W는 쓰기 작업이 성공으로 간주되기 위한 노드의 수다. (ps. 이런 시스템을 quorum-based [2]) 라고도 한다)
논문에 따르면 Amazon에서 가장 보편적으로 사용되는 설정은 (N=3, R=2, W=2)이다. 이 설정에서는 3개 노드 중에 2개에서만 성공 응답을 받아도 클라이언트에게 바로 성공 메시지를 보낸다. 이와 다르게 (N=3, R=1, W=3)으로 설정한다면 read는 하나에서만 응답을 받아도 되어 매우 빠르고, write에서 일관성을 보장하지만 Write Availability가 떨어질 수 있는, 그림 1에서 설명한 전통적 데이터베이스 디자인과 같게 된다. (N=3, R=1, W=1)에서는 매우 낮은 consistency를 보일 테지만 가장 높은 성능을 끌어낼 수 있을 것이다.
Amazon 내부에서도 매우 다양한 서비스가 존재하고, consistency level 요구도 각자 다를 것이다 (결제 정보는 제품의 리뷰 수보다 더 높은 일관성을 요구할 것이다). 그렇기에 파라미터를 설정 가능하게 한 것은 매우 의미있어 보인다. 덕분에 가장 덜 중요한 데이터는 최대한 빠르고 저렴한 설정으로, 그보다 중요한 데이터는 가용성과 일관성을 타협하는 설정으로 전체 어플리케이션을 구성할 수 있었다.
DynamoDB의 디자인
Amazon의 CTO Werner Vogels의 블로그 All Things Distributed [3] 에는 DynamoDB가 어떻게 만들어졌는지에 대한 포스트[4]가 올라와있다. 이에 따르면 DynamoDB는 Amazon이 원래 사용하던 SimpleDB라는 데이터베이스에 Dynamo의 디자인 일부를 접목시켜 만든 것이라고 한다. 이 글에서 가장 인상 깊었던 구절은 아래였다.
It became obvious that developers strongly preferred simplicity to fine-grained control as they voted “with their feet” and adopted cloud-based AWS solutions, like Amazon S3 and Amazon SimpleDB, over Dynamo. Dynamo might have been the best technology in the world at the time but it was still software you had to run yourself. And nobody wanted to learn how to do that if they didn’t have to. Ultimately, developers wanted a service. [4]
사람들이 AWS를 (혹은 Azure, GCP 등을 포함한 전체 클라우드 시스템을) 선호하는 이유 중 하나는 뒤에서 어떤 일이 일어나는지 알 필요 없이, 이들이 제공하는 API를 가져다가 쓰기만 해도 된다는 것일 것이다. 똑똑한 Amazon 개발자라고 해서 다른 건 없었나 보다. 이들도 완성형 서비스를 쓰기를 원했고, Dynamo처럼 불완전하고 공부해야 하는 소프트웨어는 번거로워했다.
그래서일까, 기본적인 기능 위주로 써보기는 했지만 내게 DynamoDB는 사용하기 편리했고 또 다채로운 기능들을 제공했다. Dynamo와 비교해 DynamoDB에서는 많은 것들이 바뀌었을 테지만, 그럼에도 DynamoDB의 근간에는 Dynamo의 디자인 철학이 담겨있었다. 이 섹션에서는 DynamoDB의 핵심 요소들을 앞서 얘기했던 Dynamo의 핵심 아이디어와 연결지어 하나씩 설명해보려 한다.
a. 읽기 일관성
DynamoDB에서의 read operation은 기본적으로 Eventual Consistency만 보장한다. 이는 가용성을 위해 Dynamo의 주요 디자인을 계속해서 받아들인 것으로 볼 수 있다. 공식 문서에 따르면 보통 1초 이내에 모든 스토리지 위치의 데이터가 일관성을 갖게 된다고 한다. [6] (이는 반대로 이야기하면 1초 내에 읽기 작업을 요청하면 예전 버전의 데이터를 반환할 수 있다는 의미이다.) 또 전체 리전 장애에도 정상 동작할 수 있도록 replication들은 서로 격리되어있는 여러 센터에 걸쳐 저장된다고 한다.
하지만 사용자가 일관성이 보장이 된 결과를 원한다면 옵션(consistent-read)을 통해 strongly consistent read를 요청할 수 있다. 다음은 해당 문서에 있는 내용이다.
- 강력한 일관된 읽기strongly consistent read는 네트워크 지연 또는 중단이 발생한 경우에 사용이 어려울 수 있습니다. 이 경우 DynamoDB는 서버 오류(HTTP 500)를 반환할 수도 있습니다.
- 강력한 일관된 읽기는 최종적 일관된 읽기보다 지연 시간이 더 길 수도 있습니다.
- 강력한 일관된 읽기는 최종적 일관된 읽기보다 처리 용량을 더 많이 사용합니다.
이 옵션을 켜면 Dynamo 문단에서 설명했던 문제가 그대로 발생하는 것을 볼 수 있다. 완전한 일관성을 보장 받고 싶다면 가용성을 다시 tradeoff 해야한다. 하지만 상황에 따라 일부 쿼리는 가용성보다 일관성이 중요할 수 있다. DynamoDB는 Dynamo처럼 기본적으로 강한 일관성을 요구하지 않는 어플리케이션을 타겟으로 만들어졌지만, 편의성을 위해 이런 수요를 배제하기 보다는 사용자로 하여금 선택할 수 있게 만들며 유연성을 제공한다.
b. 파티션 키와 정렬 키
DynamoDB는 아래의 두 가지의 기본 키를 지원한다:
- 파티션 키Partition Key: 우리가 흔히 아는 key-value 스토리지의 키. 고유 값을 갖는다.
- 정렬 키Sort Key: 그 자체로는 고유할 필요 없이 파티션 키와 정렬 키의 쌍만 고유하면 된다. (일종의 복합 키)
두 키의 차이는 쿼리 조건의 차이라고 볼 수 있다. DynamoDB에서 파티션 키에 대해서는 오로지 == 조건 검색만 수행이 가능하다. 하지만 정렬 키는 <, ≤, >, ≥, between, begins_with 등 더 풍부한 연산을 제공한다. DynamoDB는 왜 이런 복잡한 키 구성을 가지고 있을까?
Dynamo는 내부적으로 데이터 분배를 위해 Consistent Hashing [7] 기반의 알고리즘을 사용한다. Consistent Hashing은 간단히 이야기하자면 노드의 개수가 변동되는 상황에서 요청을 분산하는 방법이다. 그리고 이 알고리즘의 이름에서부터 나타나지만 위치를 결정하는 것은 해시 알고리즘이다. 중앙에 마스터 노드가 존재하여 어떤 키가 어떤 노드에 저장되는지 직접 관리하는 방식이 아니다. 대신에 클라이언트가 모두 동일한 알고리즘을 가지고 바로 노드에 요청하는 방식이다. 중앙 관리형이 아니며, 또 해시 기반이기 때문에 정렬된 데이터 구조를 가질 수 없다. 때문에 Dynamo을 기반으로 한 DynamoDB 또한 비슷한 구조로 인해 파티션 키로 range query를 사용할 수 없다.
하지만 range query의 지원 여부는 NOSQL을 포함한 데이터베이스의 편의성에 많은 영향을 준다. 단적으로 예를 들면 range query를 지원하지 않는 시스템에서 a < key < b 인 아이템을 찾기 위해서는 모든 레코드를 scan 해야 한다. DynamoDB에서의 정렬 키Sort Key는 이러한 불편함을 보완하기 위해 만들어낸 개념이라고 생각된다. 예를 들면 게시판 시스템에서 테이블 1과 같은 구조로 스키마를 사용한다고 가정하자. 게시글과 댓글 모두 독립적인 레코드로 보되, 댓글의 경우에는 게시글과 파티션 키를 공유하도록 했다. 이 경우 게시글 ID는 == 연산만 사용할 수 있지만 댓글 ID에 대해서는 더 다양한 조건을 지정할 수 있다. PartitionKey="Article-123" AND SortKey between "Comment-10" and "Comment-20" 같은 쿼리가 수행될 수 있다는 말이다.
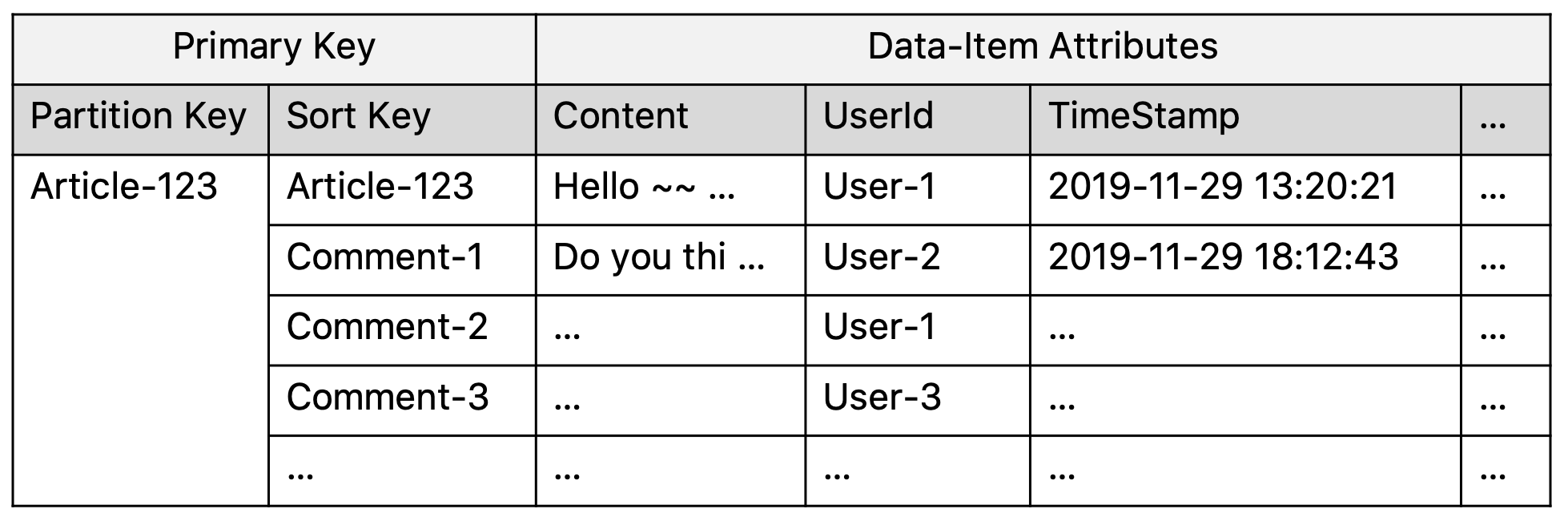 테이블 1. DynamoDB의 샘플 테이블 스키마
테이블 1. DynamoDB의 샘플 테이블 스키마
DynamoDB에서 같은 파티션 키를 갖는 아이템은 같은 노드에 저장된다. 위 테이블에서 Article-123 이라는 게시글과 그 게시글에 달린 댓글 모두가 실제로 물리적으로 같은 곳에 있다는 소리다. (실제로는 가상화되어 물리적으로 다를지도 모른다. 하지만 편의를 위해 물리적으로 같은 곳이라고 가정하자.)
파티션 키는 어떤 노드에 데이터를 저장할지 결정한다. 하지만 파티션 키가 노드 내부(internal)의 위치까지 결정할 필요는 없다. 노드 내부에서 B-Tree 같은 자료 구조를 이용하여 아이템을 저장할 수 있는데, 이때의 인덱스로 파티션 키를 계속 사용하지 않아도 된다는 것이다. DynamoDB에서는 이 경우 정렬 키를 내부 인덱스로 사용한다. 파티션 키를 통해 레코드가 어떤 노드에 저장되어야 하는지를 결정하고(external location), 정렬 키로 노드 내부에서의 아이템 위치를 결정하는 것이다(internal location).
다시 앞서 말했던 PartitionKey="Article-123" AND SortKey between "Comment-10" and "Comment-20" 라는 쿼리를 살펴보자. DynamoDB는 해시 알고리즘을 통해서 Article-123라는 파티션 키를 가진 아이템이 어떤 노드에 위치해있는지를 먼저 알아낸다. 이후 해당 노드의 내부에서 Comment-10 ≤ SortKey ≤ Comment-20인 데이터를 조회한다. 노드 내부에서 정렬 키에 대해서 인덱스를 사용하고 있을 것이므로 데이터 조회에 fullscan을 할 필요 또한 없다.
Consistent Hashing 기반의 분산 스토리지는 중앙 관리로 인한 문제를 최소화한다. 하지만 이 디자인은 단일 대상 검색(key='A')만 가능하지 range query(a < key < b)를 사용할 수 없다는 제약이 있다. DynamoDB에서는 성능을 이유로 기능성의 일부를 포기했지만, 꽤 괜찮은 타협점으로 파티션 키와 정렬 키라는 것을 만들어 낸 것이라 볼 수 있다. 이들의 고민과 디자인 철학을 이해하고 나면 보다 더 나은 스키마를 설계할 수 있을 것이라 생각한다. 아래는 scale-out이 제대로 될 수 없는 잘못된 설계인데, DynamoDB가 내부적으로 어떻게 동작하는지를 알면 더 쉽게 문제를 발견할 수 있을 것이다.
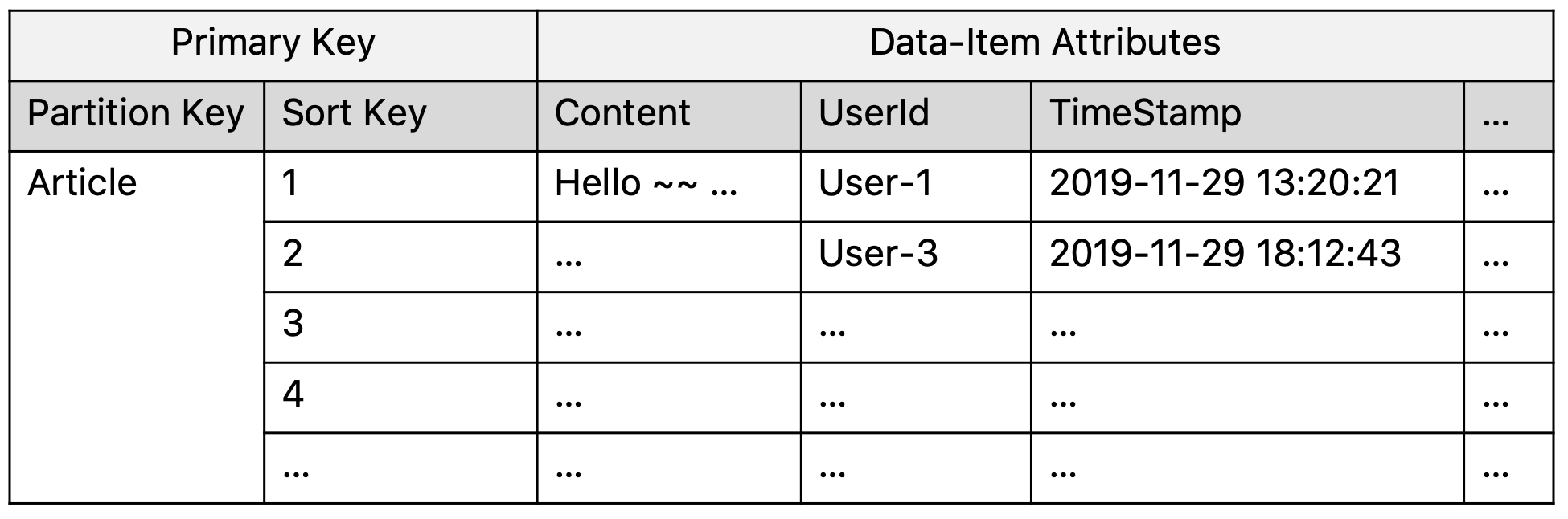 테이블 2. DynamoDB의 잘못된 테이블 스키마. 게시글이 무수히 늘어나도 물리적으로 하나의 노드에 모든 게시글들이 위치하게 된다.
테이블 2. DynamoDB의 잘못된 테이블 스키마. 게시글이 무수히 늘어나도 물리적으로 하나의 노드에 모든 게시글들이 위치하게 된다.
c. 보조 인덱스
RDBMS를 사용할 때에도 스키마 디자인에 있어 인덱스는 매우 중요했다. DynamoDB는 기본적으로 데이터베이스로서 사용할 수 있는 서비스다. 인덱스 기능 없이 오직 primary키로만 쿼리를 해야 한다면 편의성에 제약이 많아진다. 이러한 수요를 해결하기 위해 DynamoDB에서는 보조 인덱스Secondary Index라는 기능을 제공한다.
DynamoDB가 기존 RDMS와 다른 점은 인덱스가 만들어졌을 때 인덱스에 대한 B-Tree만 만드는 것이 아니라, 아예 해당 인덱스가 Primary Key가 되는 별도의 테이블을 만든다는 것에 있다. 그리고 별도의 테이블이 만들어진다는 것은 인덱스가 원본 테이블과는 물리적으로 다른 노드에 위치할 수 있다는 것을 의미한다. 테이블 1에서 UserId 컬럼에 대해 보조 인덱스를 걸었을 때 새로 생기는 테이블은 아래와 같다. 이 두 테이블은 달라 보이지만 레코드만 놓고 보면 그 내용은 모두 같다. 즉 보조 인덱스 테이블도 일종의 replication으로 취급될 수 있다. (ps. 레코드 내용이 항상 같지는 않을 수도 있다. 인덱스 테이블에 모든 레코드를 복제하지 않고 일부 속성만 프로젝션 할 수도 있다. 물론 이 경우에도 replication으로 취급 할 수 있다.)
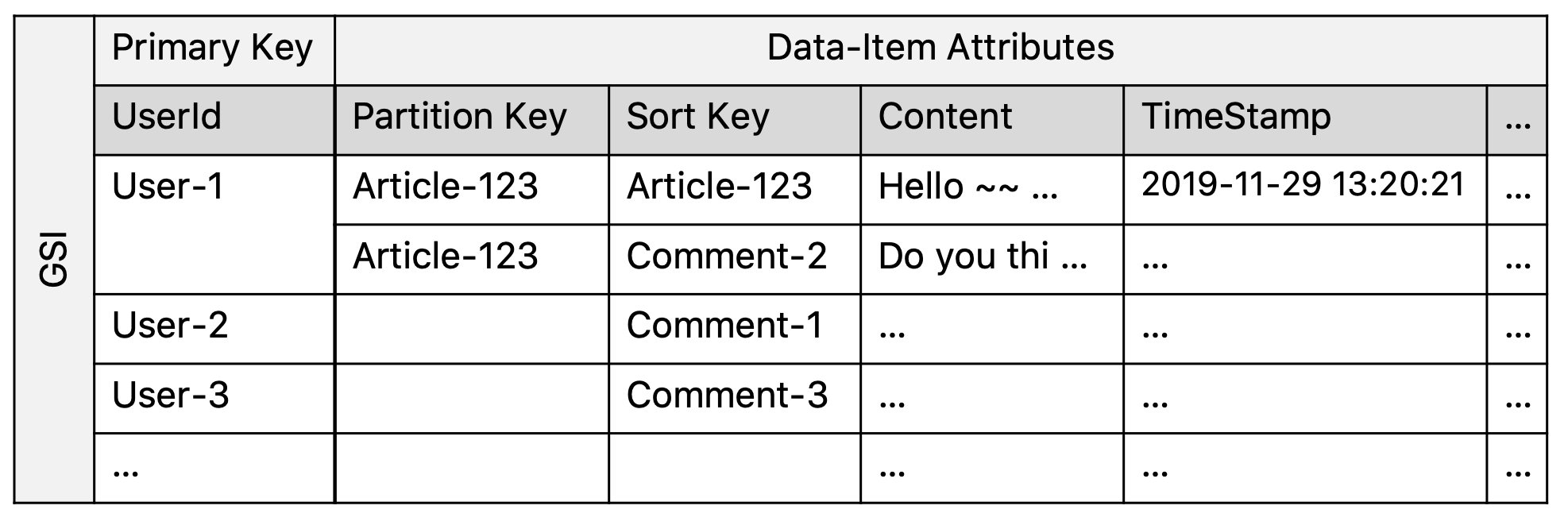 테이블 3. UserId 컬럼을 Partition Key로 둔 GSI 테이블
테이블 3. UserId 컬럼을 Partition Key로 둔 GSI 테이블
인덱스는 본래 read operation을 위한 것이기에 인덱스 테이블에 write operation이 바로 수행될 일은 없을 것이다. 실제로 DynamoDB에서 인덱스에 대한 Put API 같은 것은 존재하지 않는다. 대신에 기본 테이블에 write operation이 수행되면 인덱스 테이블로 업데이트가 전파된다. 그리고 이때에도 완전한 consistency 대신 Eventual Consistency만 보장한다.
생각해보라. 만약 인덱스에 테이블에 대해서 완전한 consistency를 보장한다면, 인덱스가 많아질수록 그 수에 비례해 write availability가 떨어질 것이다 (3개의 노드 모두가 operation을 성공할 확률과 9개의 노드가 모두 성공할 확률은 분명 다르다). 이 때문인지 a. 읽기 일관성에서 언급했던 Consistent Read 옵션도 글로벌 보조 인덱스에서는 아예 지원되지 않는다.
위에서 설명한 인덱스는 정확히는 글로벌 보조 인덱스(Global Secondary Index; GSI)이고, DynamoDB에는 로컬 보조 인덱스(Local Secondary Index; LSI)라는 하나의 인덱스가 더 존재한다. LSI는 기본 테이블과 파티션 키는 공유하지만 다른 컬럼을 정렬 키로 사용할 수 있게 하는 인덱스이다. GSI와 달리 LSI는 강력한 일관성을 보장한다. 대신에 LSI는 GSI와 달리 해당 파티션 키의 노드와 같은 곳에 테이블이 만들어진다. 즉 LSI는 충분히 scalable 하지 않는다. 그래서인지 실제로 AWS의 공식 문서에서도 LSI보다 GSI를 사용하는 것을 권장하고 있다. [8]
이러한 인덱스 디자인은 기본적으로 Eventual Consistency만 보장하자는 가정아래였기에 가능한 설계이라고 생각된다. 그 덕분에 편의성을 높이면서도 Dynamo에서 가장 중요하게 여겼던 가용성과 확장성은 여전히 잘 보장하고 있다.
d. 온디맨드/프로비저닝된 모드
DynamoDB를 AWS에서 사용하면서 가장 먼저 요구하는 설정이 아마 온디맨드로 할 것이냐 프로비저닝된 모드로 할 것이냐 였던 것으로 기억한다. 온디맨드 모드로 설정한다면 다른 설정 없이 DynamoDB가 알아서 값을 조정하고, 프로비저닝된 모드를 사용할 경우 어플리케이션에 필요한 초당 읽기 및 쓰기 유닛 수를 지정해야 한다. 아마 처음 DynamoDB를 사용하는 사람들은 대부분 온디맨드로 시작했다가, 더 최적화된 설정이 필요하면 프로비저닝된 모드로 넘어갈 것이다.
다시 잠깐 Dynamo 문단에서 설명했던 N, R, W 파라미터 이야기를 꺼내자면, 이 파라미터가 유연성을 주기는 했지만 한편으로 불편한 점들도 많았다고 한다. 왜냐하면 Dynamo를 쓰기 위해서는 본인들이 만드는 시스템이 어느 정도 consistency를 가졌을 때 최적인지를 알아야 하고, 직접 실험을 거쳐가며 파라미터 값을 세팅해야 했기 때문이다. DynamoDB를 다루는 Werner Vogels의 글에서도 Dynamo는 커머스 플랫폼의 코어 서비스 정도에서만 잘 활용되었고 그 밖으로는 벗어나지 못했는데, 그 이유가 복잡한 시스템 이해 과정과 의사결정의 수고로움 때문이었다고 말한다. [5]
Also, they needed to make complex tradeoff decisions between consistency, performance, and reliability. This operational complexity was a barrier that kept them from adopting Dynamo. [5]
DynamoDB에서는 사용자가 N, R, W 같은 파라미터를 설정할 필요가 없다. 내가 알기로는 설정할 수 있는 방법도 없는 것으로 안다. 데이터베이스 사용자가 총 몇 개의 replication 노드를 사용할지, read operation시에는 그중 몇 개의 노드에 요청할지 같은 값을 정하는 작업은 쉬운 일이 아니다. 하지만 이들이 피크타임에 총 몇 명의 유저가 모이는지, 초당 트랜잭션은 얼마나 되는지는 훨씬 쉽게 알 수 있다. DynamoDB에서는 모호한 파라미터 대신에 더 직관적인 ‘초당 read unit 수’, ‘초당 write unit 수’ 같은 값을 지정한다. 내부적인 파라미터 세팅은 DynamoDB 내부에서 알아서 할 것이다.
온디맨드/프로비저닝된 모드 기능은 모호했던 파라미터 설정을 사용자 친화적으로 바꿔서 디자인한 기능으로 해석해도 될 듯하다. Dynamo의 N, R, W는 분명 과감하고 신선했던 아이디어였지만, 한 층 사용자 입장에서 더 생각하여 이런 디자인이 만들어지지 않았을까.
결론
DynamoDB에는 생소한 개념이 많이 등장하고, 무언가 제약 상황이 많아 보인다. 왜 이들은 완전한 일관성을 보장하지 않는가. 왜 인덱스를 설정하면 전용 테이블을 따로 만드는 것인가. 또 GSI 테이블에는 왜 Consistent Read 옵션을 사용할 수 없을까. DynamoDB 공식 문서에는 이런 질문들에 대한 답이 존재하지 않는다.
물론 굳이 이런 질문에 답하지 않아도 DynamoDB를 사용하는 데에는 문제가 없을 것이다. 하지만 Dynamo 논문을 통해서 Amazon이 어떤 문제를 해결하려 했었고 Werner Vogels의 글을 통해 어떤 철칙을 바탕으로 DynamoDB를 디자인했는지 알고 난 이후에, 나는 더 쉽게 DynamoDB를 이해하고 빠르게 배울 수 있었다. Dynamo는 write availability라는 문제를 해결하기 위해 만들어졌었고, 이를 위해 consistency를 일부 포기하자는 아이디어로부터 나왔다. 이 관점에서 DynamoDB의 디자인을 본다면, DynamoDB를 더 잘 이해하고 더 잘 사용할 수 있으리라 생각한다.